Introduction
Now that we understand the theory behind Elo Ratings, let’s take a look at how to calculate them and how to make them more relevant to football.
Calculating Elo Ratings
The equation for calculating a team’s Elo rating is shown below in Figure 1, where $Ra_{new}$ is the team’s new Elo rating after a match, $Ra_{old}$ is the team’s previous Elo rating before the match and $k$ is a weighting factor. $Sa$ is the outcome of the match normalised to the range 0–1 so that 0 is a loss, 0.5 is a draw and 1 is a win.
$Ra_{new}=Ra_{old}+k(Sa-Ea)$
Figure 1: Elo Rating equation
$Ea$ is the expected probability of the team winning the match and is calculated using the equation in Figure 2 where $Rb-Ra$ is the difference in Elo ratings between the two teams.
$Ea=1/1+10^{(Rb-Ra)/400}$
Figure 2: Expected win probability equation
Win Expectancy
The calculation for $Ea$ is actually slightly different from the original Elo equation as it uses a logistic distribution for player performances rather than a normal distribution. The use of the logistic distribution stems the chess community, who suggested that it fit player performances better than the normal distribution did. In effect, the differences between the two are relatively minor, with the logistic curve skewing more performances to the tails of the distribution, meaning players are slightly more likely to over- or under-perform (Figure 3).
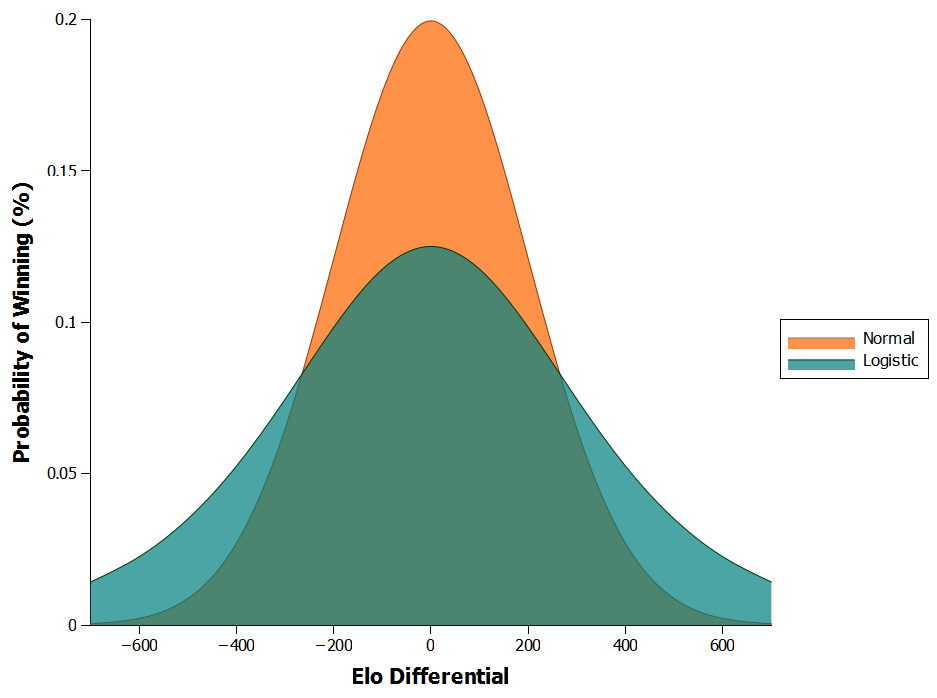
Figure 3: Comparison of logistic and normal distributions
Weighting Factor
The constant $k$ in the equation controls how many points are gained or lost each match. Increasing k will apply more weight to recent matches while lowering it will allow historic matches to have more of an effect on a team’s Elo rating. Therefore, using an inappropriate rating for $k$ may lead to inaccurate Elo ratings being calculated.
Eloratings.net is a website that applies Elo ratings to international football. They use a weighting of 60 for a world cup final, 50 for continental championship finals and major intercontinental tournaments, 40 for World Cup and continental qualifiers, 30 for all other tournament matches and 20 for international friendly matches. However, since none of these ratings apply directly to domestic football and since Eloratings.net does not explain how they were determined I decided to calculate my own.
Using Least Squares I optimized the value of $k$ to minimize the error of the predicted outcomes versus the actual match results using data from the English Premier League. Overall, the most accurate predictions were obtained using a value of 15 for $k$.
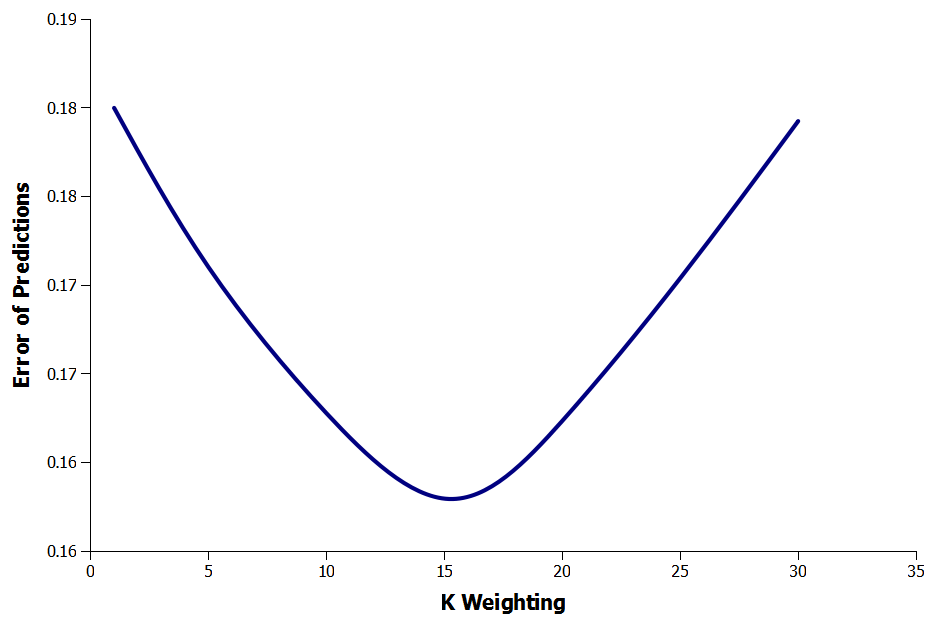
Figure 4: Effect of k on error of Elo prediction
Goal Difference
Another modification we can do to make the Elo ratings more applicable to football is to take into account the number of goals scored so that beating the opposition by two goals for example is better than wining by just one.
We can do this by scaling $k$ by the goal difference so that the larger the difference the more points are gained by the victor and the more lost by the loser. There are a number of ways this can be done but in my method each additional goal a team scores becomes increasingly less important. For example, going from 1–0 to 2–0 is much more critical in terms of winning a game than going from 8–0 to 9–0.
Eloratings.net used a similar approach where their scaling reduces the weightings for goal differences of two and three. However, for goal differences of four upwards their scale (intentionally or unintentionally) becomes linear and from then on applies equal weightings to each additional goal scored. Instead, I have used a sigmoid function to smoothly reduce the weightings of each goal scored to create the curve shown in Figure 5, which is then used to produce the scaling factors shown in Table 1
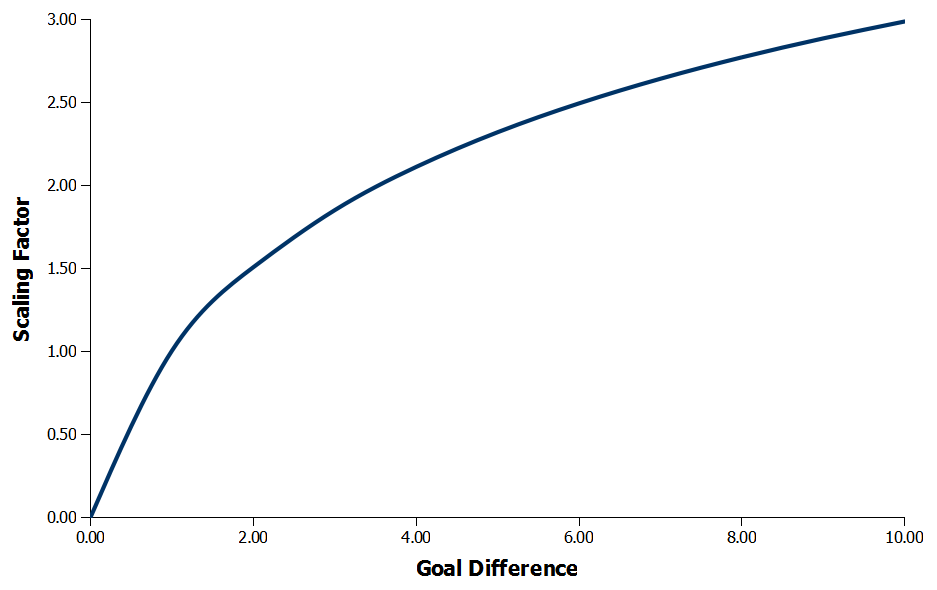
Figure 5: Goal difference scaling factor smoothed using a sigmoid
| Goal Difference | Scaling Factor |
| 10.00 | 2.99 |
| 9.00 | 2.88 |
| 8.00 | 2.77 |
| 7.00 | 2.64 |
| 6.00 | 2.49 |
| 5.00 | 2.32 |
| 4.00 | 2.11 |
| 3.00 | 1.85 |
| 2.00 | 1.51 |
| 1.00 | 1.00 |
Table 1: Goal difference scaling factors
Home Advantage
If two teams with equal Elo ratings play each other then in theory they should both have an identical chance of winning the match; however, in football the home team always has a noticeable advantage.
Looking back at the 2011–2012 English Premier League season, home wins accounted for 47% of results compared with just 24% for away wins. The remainder of the results are draws, which Elo ratings consider to be half a win, so including these gives us a final win expectancy of 61% for the home team and 39% for the away team.
To account for this we can give the home team’s Elo a temporary boost of 75 points. For two equally matched teams this then raises the win expectancy for the home team from 50% to 61%, matching what we see in the English Premier League.
Relegations and Promotions
Another issue to consider is how to deal with relegations and promotions. We could calculate Elo ratings for each tier of the league so that a team already has a rating when it gets promoted or alternatively we could award each promoted team the average Elo rating of 1500. A nice feature of Elo ratings is that they are self-correcting so although these arbitrary ratings may not be accurate they would gradually alter to the correct level.
This does have the unfortunate side effect of skewing the other team’s Elo values though. The gain and loss of Elo points is zero sum, meaning that for every Elo point a team gains another team has to lose one. So adding in teams with different Elo ratings would distort the values of other the team’s ratings by altering the overall number of points available in the league.
The simplest way to deal with this problem is to give the promoted teams the equivalent relegated team’s Elo rating. So the best promoted team takes the Elo rating of the best relegated team, the second best promoted team takes the Elo rating of the second best relegated team, and so on. This then keeps the correct number of Elo points in the league and maintains the parity in points between teams.
Conclusions
Elo ratings are a really quick and easy way to compare teams directly and calculate win expectancies. While techniques like the Pythagorean Expectation looks at how teams perform over a long period of time, Elo ratings can be used to look at teams on a match–by–match basis.