Introduction
Unfortunately time caught up with me last week and I was unable to post any predictions from my Eastwood Index. However, since then I have been busy validating the results to see how accurate the predictions really are using the 296 matches played in the English Premier League so far this season.
Ranked Probability Scores
I have previously discussed the problems of trying to determine the accuracy of probability-based models and Jonas posted a suggestion in the comments section recommending the use of ranked probability scores, which turned out to be a really interesting idea.
Ranked probability scores were originally proposed by Epstein back in 1969 as a way to compare probabilistic forecasts against categorical data. Their main advantage over other techniques is that as well as looking at accuracy, they also account for distance in the predictions e.g. how far out inaccurate predictions are from what actually happened.
They are also easy to calculate. The equation for ranked probability scores is shown in Figure 1 for those of a mathematical disposition, where $K$ is the number of possible outcomes, and $CDF_{fc}$ and $CDF_{obs}$ are the predictions and observations for prediction $k$.
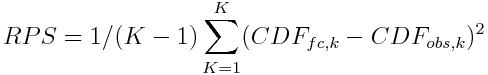
Interpreting Ranked Probability Scores
Ranked probability scores range between 0–1 and are negatively orientated meaning that the lower the result the better. For simplicity, you can think of them representing the amount of error in the predictions where a score of zero means your predictions are perfect.
The Results
I started off looking at how well I would have done if I had just guessed at random for each match in the English Premier League this season rather than using the Eastwood Index and obtained a ranked probability score of 0.231.
Next, I looked at how well the bookmaker’s odds predicted matches. To do this I aggregated the odds from multiple bookmakers, partly to reduce the comparisons needed and partly because aggregating data often improve predictions and I wanted to give the Eastwood Index the toughest test possible. This gave a ranked probability score of 0.193 for the bookmakers.
Finally I calculated the score for the Eastwood Index and got…
drum roll please
a ranked probability score of 0.191. Okay, it is not much lower than the bookmakers but it does mean that so far this season the Eastwood Index has been more accurate at predicting football matches than the combined odds of the gaming industry which is really pleasing for me.
Conclusions
Most importantly though this suggests that the Eastwood Index works. I had originally set myself the target of being able to compete with the bookmakers as I consider them to be gold standard prediction for football. These are large companies employing professional odds compilers to generate their odds so for me to be able to beat them, even by a small amount, using a bunch of equations is a big success for the Eastwood Index.
It is still early days and it is still a relatively small number of predictions (n=296) so I will be continuing to monitor the results to check the accuracy doesn’t change over time. It is a fantastic start though and great inspiration to continue developing and improving the Eastwood Index further!